-
[Machine Learning] 인공 신경망(Artificial Neural Network)Informatik 2022. 2. 18. 18:19반응형
※ [Machine Learning] 베이즈 결정 이론(Bayesian Decision Theory)
[Machine Learning] 베이즈 결정 이론(Bayesian Decision Theory)
지도 학습(Supervised Learning)의 분류(Classification)에 해당하는 머신러닝(Machine Learning) 기법인 베이즈 결정 이론은 일상생활에서 흔하게 볼 수 있고 사용할 수 있는 기법이다. 예를 들어, 스팸 메일을.
minicokr.com
데이터 분포(Data Distribution)를 정확히 예측한 경우, 베이즈 최적 분류기(Bayes Optimal Classifier) 보다 더 정확한 이진 분류기가 없다. 하지만 실생활에서 데이터의 분포를 예측하는 것은 어렵기 때문에 항상 베이즈 최적 분류기로 좋은 모델을 형성할 수 없다.
※ [Machine Learning] 퍼셉트론 인공신경망(Perceptron Artificial Neural Network)
[Machine Learning] 퍼셉트론 인공신경망(Perceptron Artificial Neural Network)
※ [Machine Learning] 선형 분류(Linear Classification) [Machine Learning] 선형 분류(Linear Classification) 선형 분류는 일차원 혹은 다차원 데이터들을 선형 모델(Linear Model)을 이용하여 클래스들로 분..
minicokr.com
퍼셉트론은 데이터의 분포를 알 필요 없이 데이터의 평균(Mean)을 사용해 이진 분류를 한다. 하지만 두 클래스 간 데이터가 가까워지면 정사영된 공간에 클래스 간의 중첩도 발생해 정확한 분류를 하지 못한다.
※ [Machine Learning] 피셔의 선형 판별 분석(Fisher Linear Discriminant Analysis)
[Machine Learning] 피셔의 선형 판별 분석(Fisher Linear Discriminant Analysis)
※ [Machine Learning] 상관계수(Correlation Coefficient) [Machine Learning] 상관계수(Correlation Coefficient) 상관계수는 두 변수 사이의 통계적 관계를 표현하기 위해 특정한 상관관계의 정도를 수치적으로..
minicokr.com
피셔의 LDA는 평균뿐만 아니라 데이터의 공분산(Covariance)까지 고려해 클래스 간 분산(Between Class Scatter)을 최대화하고 클래스 내 분산(Within Class Scatter)은 최소화하여 퍼셉트론보다 더 정확하게 이진 분류를 한다. 하지만 피셔의 LDA를 구하는데 공분산의 역행렬을 계산해야 하며, 이는 고차원 데이터가 주어졌을 때 다소 비효율적이다. 또한, 이상치(Outlier)가 있을 때, 평균과 공분산에 큰 영향을 끼치며 정확성마저 떨어뜨린다.
인공 신경망은 머신러닝과 인지과학에서 생물학의 신경망에서 영감을 얻은 통계학적 알고리즘이다. 시냅스(Synapse)의 결합으로 네트워크를 형성한 인공 뉴런(Artifical Neuron)이 학습을 통해 시냅스의 결합 세기를 변화시켜, 문제 해결 능력을 가지는 모델 전반을 가리킨다. [Wikipedia]
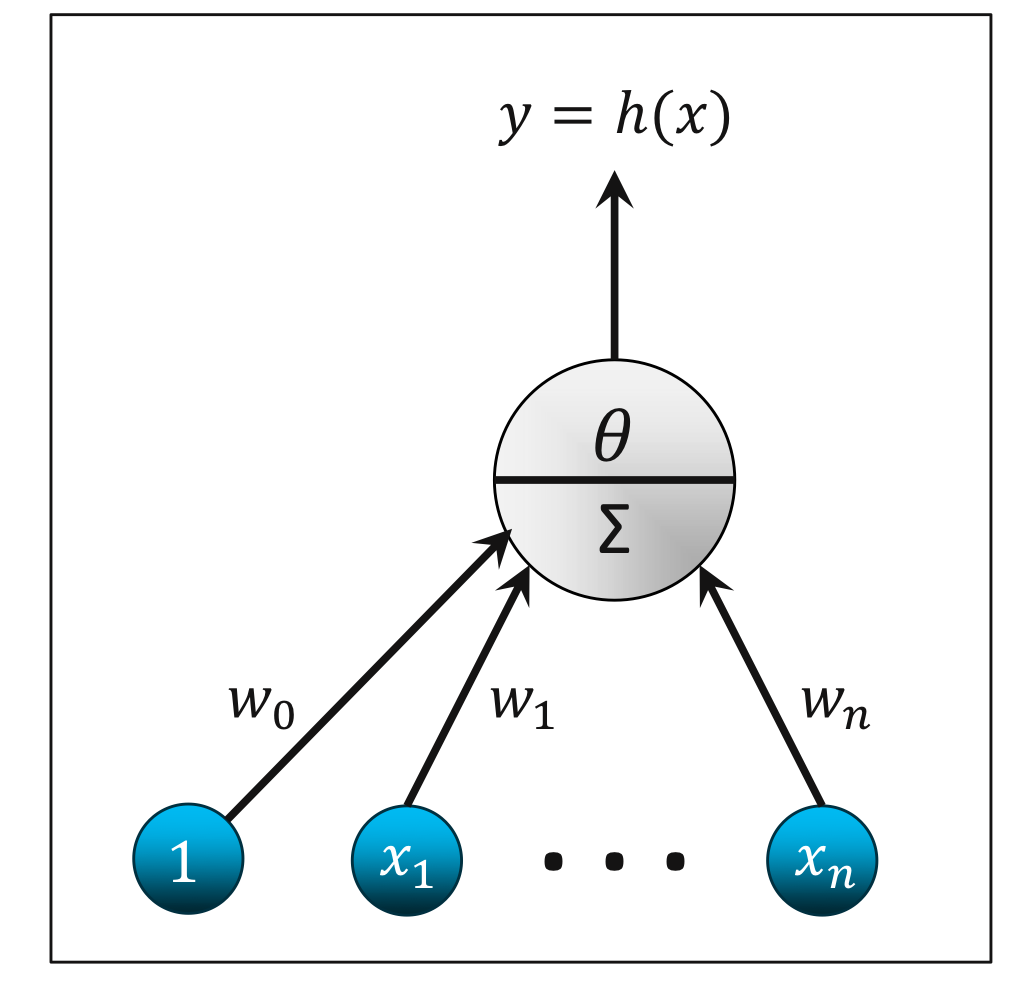
뉴런(Neuron)
일반적인 모델
입력 활성화(Input Activation)
$$a(x) = w_0 + \sum^n_{i = 1} w_i x_i = w_0 + w^{\top} x$$
출력 활성화(Output Activation)
$$h(x) = \theta (a (x)) = \theta (w_0 + w^{\top} x)$$
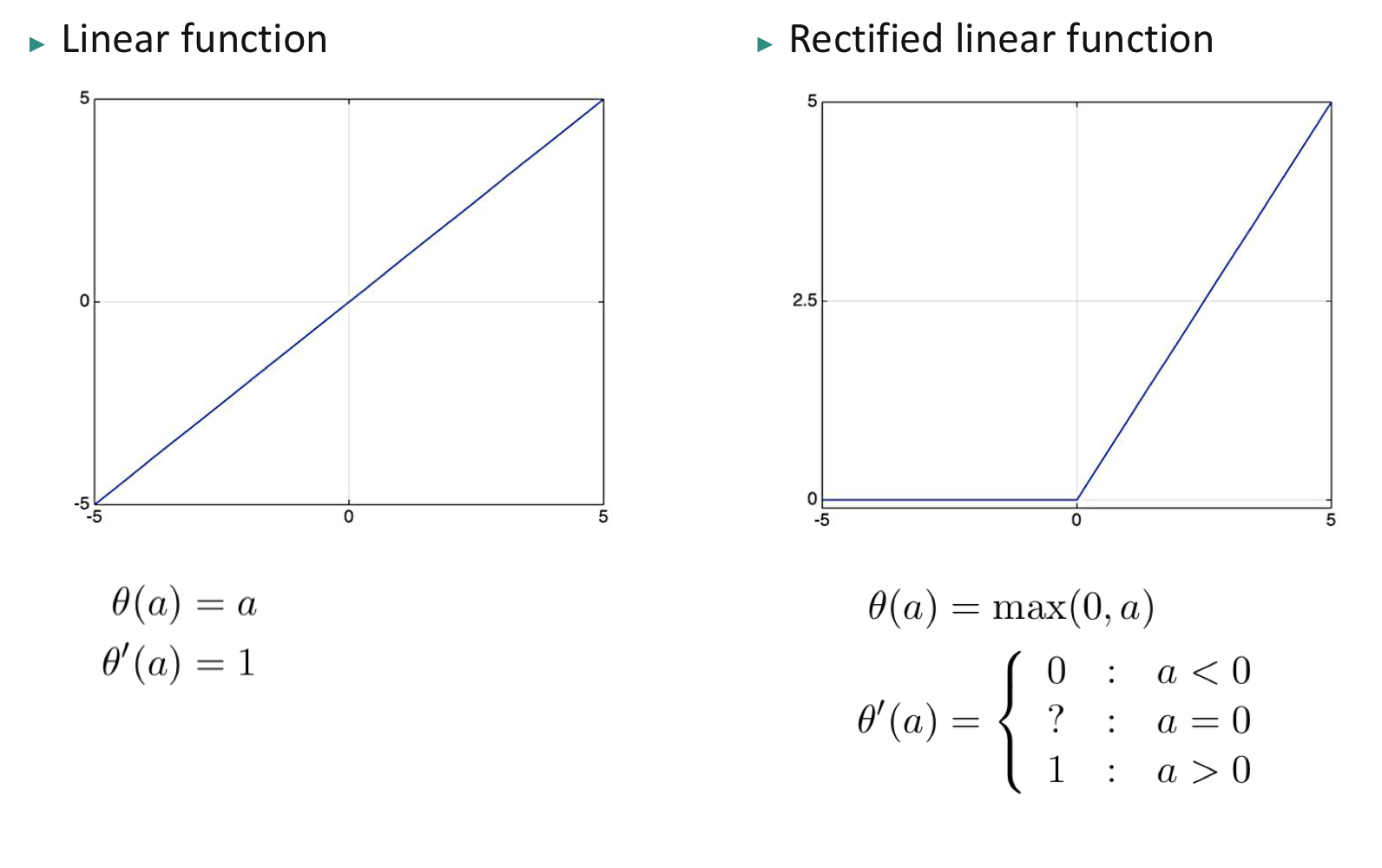
활성화 함수(Activation Function) $\theta (a)$는 전달 함수(Transfer Function)이라고도 불리며, 입력 활성화를 출력 활성화로 변형시킨다. 활성화 함수는 감소 함수(Non-decreasing Function)이다. 활성화 함수의 예로 선형 함수(Linear Function), ReLU(Rectified Linear Function), 시그모이드 함수(Sigmoid Function), 하이퍼볼릭 탄젠트 함수(Hyperbolic Tangent Function)등이 있다.

인공 뉴런은 간단하고, 미분 가능한 비선형적 다변량 함수이다. 퍼셉트론과 피셔의 LDA와 달리 비선형적인 모델까지 데이터의 분포를 알지 않고서 데이터로부터 모델을 학습할 수 있다.
※ 참고
$w_0$ 편향(Bias) $w$ 가중치(Weights) $x$ 특성 벡터(Feature Vector) $a(x)$ 입력 활성화(Input Activation) $\theta (a)$ 활성화 함수(Activation Function) $h(x)$ 출력 활성화(Output Activation)
선형 회귀(Linear Regression)
활성화 함수
선형 함수 $\theta (a) = a$.
조건
학습 셋 $(x_1, y_1), \cdots, (x_m, y_m) \in \mathbb {R}^n \times \mathbb {R}$.
목표
미지수 함수(Unknown Function) $f: \mathbb {R}^n \rightarrow \mathbb {R}$를 학습하여라.
손실 함수 및 비용 함수(Loss Function or Cost Function)
평균 제곱 오차 (Mean Squared Error) $J(w_0, w) = \frac {1}{2m} \sum^m_{t = 1} (h(x_t) - y_t)^2$
로지스틱 회귀(Logistic Regression)
활성화 함수
시그모이드 함수 $\theta (a) = \frac {1}{1 + \exp (-a)}$.
조건
학습 셋 $(x_1, y_1), \cdots, (x_m, y_m) \in \mathbb {R}^n \times \{0, 1\}$.
목표
미지수 함수 $f: \mathbb {R}^n \rightarrow \{0, 1\}$를 학습하여라.
손실 함수(Loss Function)
$J(w_0, w) = - \frac {1}{m} \sum^m_{t = 1} y_t \log (h(x_t)) + (1 - y_t) \log (1 - h(x_t))$
SLP(Single Layer Perceptron)
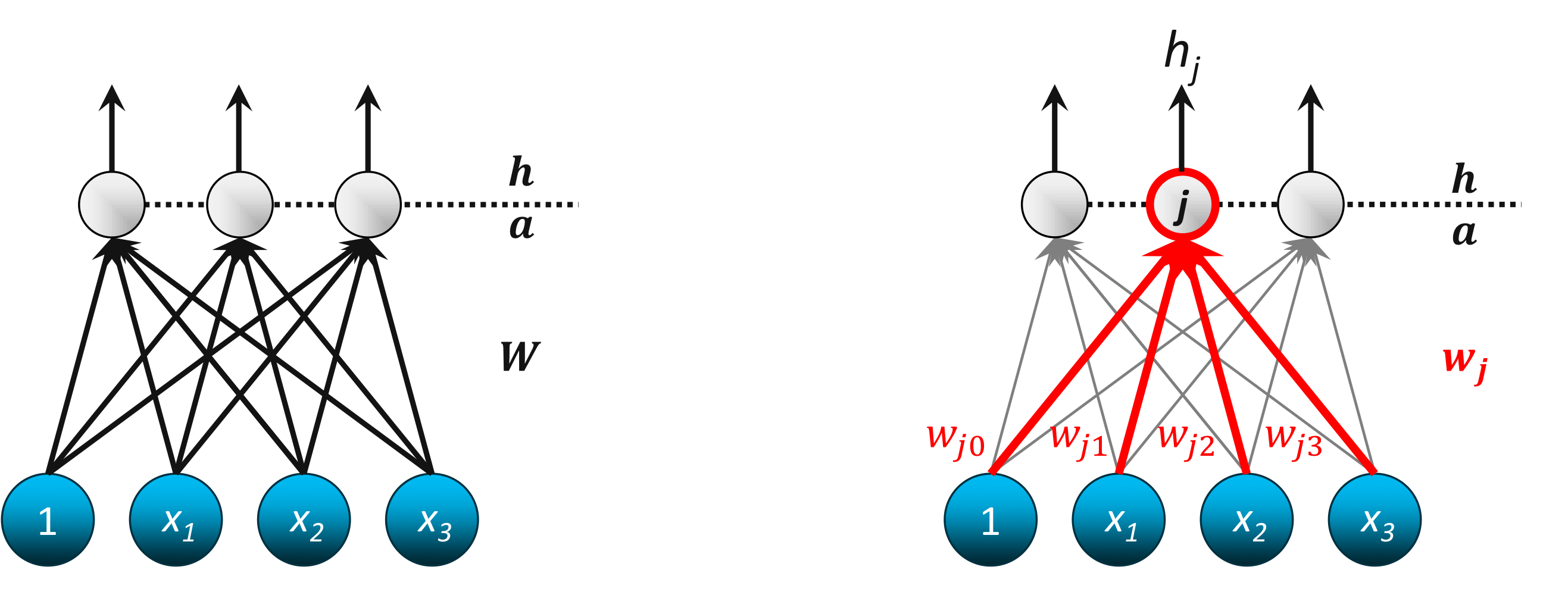
※ 참고
$x_i$ 입력 뉴런(Input Neuron) $h_j$ 출력 뉴런(Output Neuron) $W$ 가중치 행렬(Weight Matrix) $w_j = (w_{j0}, \cdots, w_{jn})$ 출력 뉴런 $h_j$의 가중치 $w_{ji}$ $x_i$와 $h_j$를 연결하는 가중치 가중치 행렬(Weight Matrix)
$$W = \begin {pmatrix} w_{10} & w_{11} & w_{12} & w_{13} \\ w_{20} & w_{21} & w_{22} & w_{23} \\ w_{30} & w_{31} & w_{32} & w_{33} \end {pmatrix}$$
출력
$j$ 번째 출력 뉴런
$$h_j = \theta(a_j) = \theta (w^{\top}_{j} x)$$
출력 벡터
$$h = \theta (Wx)$$
소프트맥스 회귀(Softmax Regression)
소프트맥스 활성화(Softmax Activation)
$$\theta (a_j) = \frac {\exp (a_j)}{\sum_k \exp(a_k)}$$

조건
학습 셋 $(x_1, y_1), \cdots, (x_m, y_m) \in \mathbb {R}^n \times \{1, \cdots, c\}$.
목표
미지수 함수 $f: \mathbb {R}^n \rightarrow \{1, \cdots, c\}$를 학습하여라.
손실 함수
$$
\begin {split}
J(W) &= - \frac {1}{m} \sum_{t = 1} \sum^c_{j = 1} \mathbb {I} \{ y_t = j \} \log h_j(x_t) \\
&= - \frac {1}{m} \sum^m_{t = 1} \sum^c_{j = 1} \hat {y}_{t, j} \log h_j(x_t)
\end {split}
$$증명


MLP(Multi Layer Perceptron)
기존에 공부했던 퍼셉트론의 한계에서 알아봤듯이, SLP는 이진 분류만이 가능하다. 더 복잡한 구조를 갖는 모델을 학습하려면 뉴런인 집합인 계층(Layer)의 수를 늘린 MLP 모델을 사용해야 한다.
$L$-계층 네트워크(L-layer Network)는 입력층(Input Layer), 출력층(Output Layer), 그리고 그 사이의 $L - 1$ 개의 은닉층(Hidden Layer)으로 구성된다.
계층 $l > 1$의 뉴런 $j$은 이전 계층인 $l - 1$의 모든 뉴런 $i$으로부터 각각 가중치 $w^{(l)}_{ji}$만큼 입력받는다. 추가적으로 편향은 $w^{(l)}_{j0}$로 표현되었다.


MLP를 모델링할 때 고려할 사항들은 다음과 같다. (※ 초모수(Hyperparameter))
- 은닉층의 개수
- 각 은닉층의 뉴런의 개수
- 활성화 함수
- 손실 함수
순전파(Forward Propagation)
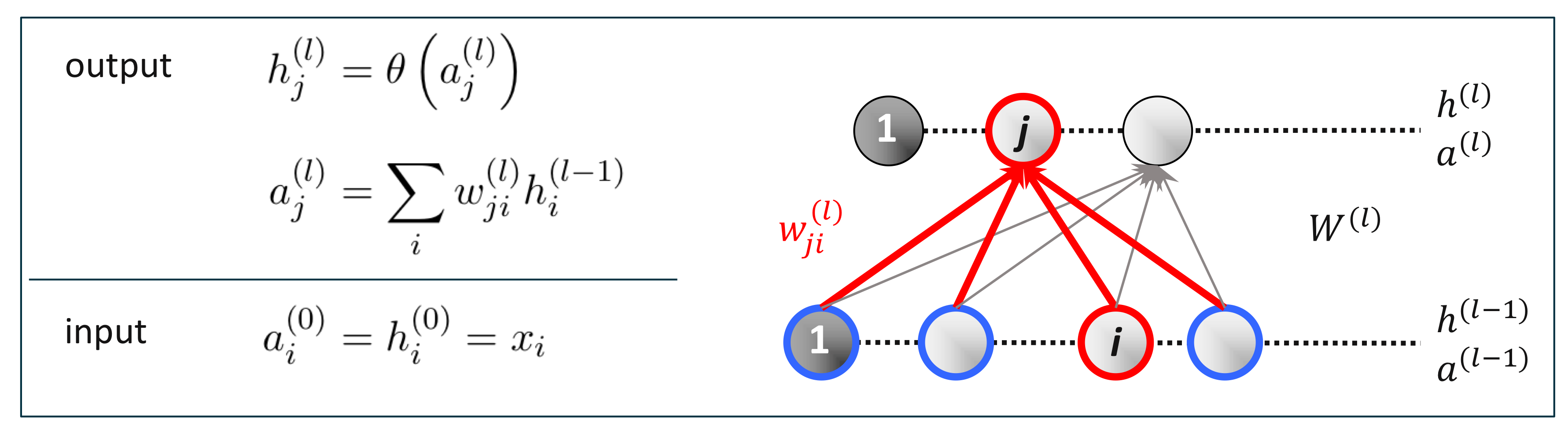
목표
네트워크 함수(Network Function)의 출력 값을 계산하여라.
절차
아랫단 계층에서 윗단 계층으로의 방향으로 각 뉴런의 출력 값을 계산한다.
예시

보편 근사 정리(Universal Approximation Theorem):
충분히 많은 뉴런을 갖는 인공 신경망은 거의 모든 비선형 함수를 근사화할 수도 있다. [Hornik, 1991]
역전파(Back Propagation)
가설 공간(Hypothesis Space) $\mathcal {H} = \{h_w: \mathbb {R}^n \rightarrow \mathbb {R}^c, W \in \vee \}$
- 초모수 (예를 들어, 계층의 개수, 각 계층 당 뉴런의 개수, 활성화 함수)
- 모수 $W = (W^{(1)}, \cdots, W^{(L)}) \in \vee$
조건
- 학습 셋 $(x_1, y_1), \cdots, (x_m, y_m) \in \mathbb {R}^n \times \mathbb {R}^c$
- 손실 함수 $l: \mathbb {R}^c \times \mathbb {R}^c \rightarrow \mathbb {R}$ with $l(\hat {y}, y) = \sum_k \tilde {l} (\hat {y}_k, y_k)$
- 가설 공간 $\mathcal {H} = \{h_w: \mathbb {R}^n \rightarrow \mathbb {R}^c \}$
목적
다음을 최소화하는 미지수 함수 $f: \mathbb {R}^n \rightarrow \mathbb {R}^c$를 학습하여라.
$$J(W) = \frac {1}{m} \sum^m_{t = 1} l(h_W(x_t), y_t)$$
경사 하강법(Gradient Descent)
경사 하강법으로 가중치를 업데이트하면서 최적의 가중치를 구한다.
$$w^{(l)}_{ji} \leftarrow w^{(l)}_{ji} - \eta \frac {\partial J(W)}{\partial w^{(l)}_{ji}}$$
분해(Decomposition)
$$\begin {split}
J(W) &= \frac {1}{m} \sum^{m}_{t = 1} J_t(W) \\
J_t(W) &= l(h_W(x_t), y_t)
\end {split}$$편미분(Partial Derivative)
위의 분해 공식에 체인 룰(Chain Rule)을 기반으로 모수 $w^{(l)}_{ji}$에 대해서 편미분을 하면 다음과 같다.
$$\begin {split}
\frac {\partial J(W)}{\partial w^{(l)}_{ji}} &= \frac {1}{m} \sum^m_{t = 1} \frac {\partial J_t(W)}{\partial w^{(l)}_{ji}} \\
\frac {\partial J_t(W)}{\partial w^{(l)}_{ji}} &= \underbrace {\frac {\partial J_t(W)}{\partial a^{(l)}_{j}}}_{\delta^{(l)}_j} \cdot \frac {\partial a^{(l)}_{j}}{\partial w^{(l)}_{ji}}
\end {split}$$위처럼 용이한 계산법을 위해 편미분의 어떤 부분을 델타로 치환을 한다.
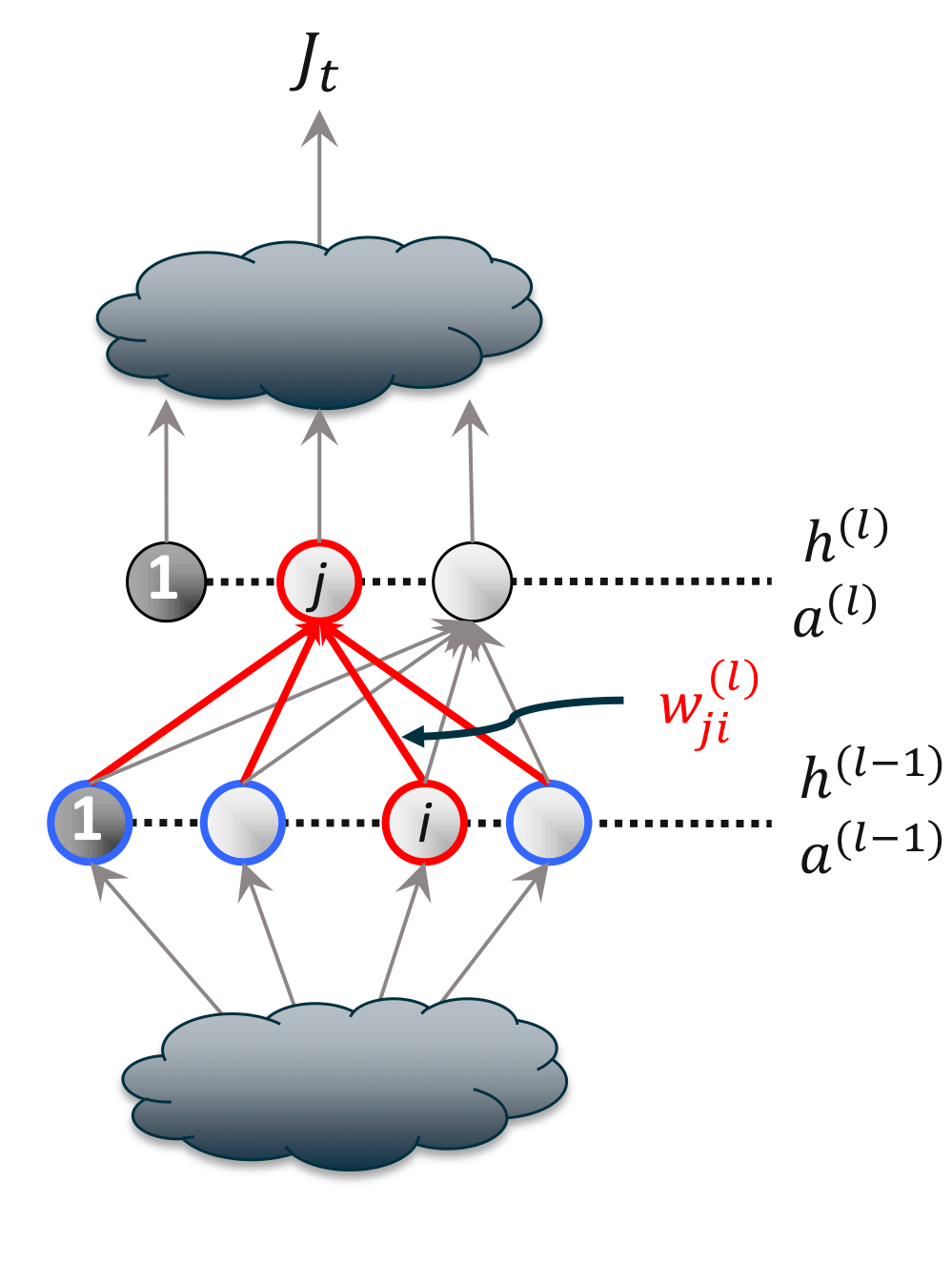
※ $a^{(l)}_j = \sum_i w^{(l)}_{ji} h^{(l - 1)}_i$
델타 규칙(Delta Rule)
$$\frac {\partial J_t(W)}{\partial w^{(l)}_{ji}} = \underbrace {\frac {\partial J_t(W)}{\partial a^{(l)}_{j}}}_{\delta^{(l)}_j} \cdot \frac {\partial a^{(l)}_{j}}{\partial w^{(l)}_{ji}} = \delta^{(l)}_j \cdot h^{(l -1)}_i$$
※ $\frac {\partial a^{(l)}_{j}}{\partial w^{(l)}_{ji}} = h^{(l - 1)}_i$
델타(Delta)
역전파를 이용해서 계산을 할 때 다음과 같은 델타가 중복적으로 사용되는데, 이는 단순히 치환 값이다.
$$\delta^{(l)}_j = \frac {\partial J_t(W)}{\partial a^{(l)}_j}$$

출력층에서는 가중치를 고려할 필요 없이 출력 활성화에 의해서만 계산되므로 출력층과 은닉층의 델타의 값은 다르다.
$$\delta^{(l)}_j = \begin {cases} \tilde {l'} (h^{(l)}_j) \cdot \theta ' (a^{(l)}_j) & : \ l = L \text { (Output Layer)} \\ \theta ' (a^{(l)}_j) \cdot \sum_k w^{(l + 1)}_{kj} \delta^{(l + 1)}_k & : \ l < L \text { (Hidden Layer)} \end {cases}$$
예 1) 역전파의 예시
$c$개의 출력 뉴런을 선형 활성화 함수로 출력하는 출력층과 시그모이드 활성화 함수를 사용하는 은닉층을 갖는 네트워크를 가정하자. 이때, 손실 함수는 다음과 같이 정의한다.
$$\begin {split}
l (h(x), y) &= \frac {1}{2} \sum^c_{k = 1} (h_k(x) - y_k)^2 \\
\tilde {l} (\hat {y}_k, y_k) &= \frac {1}{2} (\hat {y}_k - y_k)^2
\end {split}$$이전에 정의했던 델타에 의하면 출력층과 은닉층의 델타는 다음과 같다.
$$\delta^{(l)}_j = \begin {cases} (h^{(l)}_k - y) & : \ l = L \text { (Output Layer)} \\ h^{(l)}_j (1 - h^{(l)}_j) \sum_k w^{(l + 1)}_{kj} \delta^{(l + 1)}_k & : \ l < L \text { (Hidden Layer)} \end {cases}$$
※ 시그모이드 함수의 미분 $\theta ' (a^{(l)}_j) = \theta (a^{(l)}_j) (1 - \theta (a^{(l)}_j)) = h^{(l)}_j (1 - h^{(l)}_j)$
각 델타를 입력층과 출력층의 델타의 규칙에 대입하면 다음과 같다.
$$\begin {split}
\frac {\partial J_t}{\partial w^{(L)}_{kj}} &= (h^{(L)}_k - y) \cdot h^{(L - 1)}_j \text { (Output Layer)} \\
\frac {\partial J_t}{\partial w^{(1)}_{ji}} &= \delta^{(1)}_j \cdot x_{ti}
\end {split}$$
예 2) 역전파의 예시
데이터 $x_1, x_2$를 입력받아 $y$를 출력하는 MLP가 다음의 공식에 기반되어 모델링 되었다고 하자.
$$\begin {align*}
z_3 &= x_1 \cdot w_13 + x_2 \cdot w_23 & z_5 &= a_3 \cdot w_{35} + a_4 \cdot w_{45} & y = a_5 + a_6 \\
a_3 &= tanh(z_3) & a_5 &= tanh(z_5) & \\
z_4 &= x_1 \cdot w_{14} + x_2 \cdot w_{24} & z_6 &= a_3 \cdot w_{36} + a_4 \cdot w_{46} & \\
a_4 &= tanh(z_4) & a_6 &= tanh(z_6) &
\end {align*}$$다음 MLP를 그려보고, $\frac {\partial y}{\partial w_{13}}$를 구하는 식을 유도해라.
※ $tanh ' (t) = 1 - (tanh(t))^2$

역전파를 이용한 MLP의 학습
학습 셋 $(x_1, y_1), \cdots, (x_m, y_m)$을 가정했을 때, MLP를 학습하는 절차는 다음과 같다.
- 가중치 $W = (W^{(1)}, \cdots, W^{(L)})$를 초기화한다.
- 다음 절차를 종료 시까지 반복한다.
- 모든 계층에 대한 편미분 $g^{(l)}_{ji}$을 0으로 초기화한다.
- $1, \cdots, m$에 대해서 다음 절차를 반복한다. (1-3: 정방향 전파(Forward Pass), 4-6: 역방향 전파(Backward Pass))
- 첫 번째 활성화 출력은 데이터 입력값이다. $h^{(0)} = x_t$
- 모든 계층에 대하여 각각 계층 $l$의 모든 뉴런 $j$의 입력 활성화를 구한다.
$$a^{(l)}_j = w^{(l)}_{j0} + \sum_i w^{(l)}_{ji} h^{(l - 1)}_i$$ - 모든 계층에 대하여 각각 계층 $l$의 모든 뉴런 $j$의 출력 활성화를 구한다.
$$h^{(l)}_j = \theta (a^{(l)}_j)$$ - 출력층의 모든 뉴런 $k$의 델타를 구한다.
$$\delta^{(L)}_k = \tilde {l'} (h^{(L)}_k) \cdot \theta ' (a^{(L)}_k)$$ - 출력층을 제외한 모든 계층에 대해서 각각 계층 $l$의 모든 뉴런 $j$의 델타를 구한다.
$$\delta^{(l)}_j = \theta ' (a^{(l)}_j) \cdot \sum_k w^{(l + 1)}_{kj} \delta^{(l + 1)}_k$$ - 모든 계층에 대해서 각각 계층 $l$의 모든 뉴런 $j$의 편미분을 업데이트한다.
$$g^{(l)}_{ji} \leftarrow g^{(l)}_{ji} + \delta^{(l)}_j h^{(l - 1)}_i$$
- 모든 계층에 대하여 각각 계층 $l$의 모든 뉴런 $j$의 가중치를 업데이트한다.
$$w^{(l)}_{ji} \leftarrow w^{(l)}_{ji} - \frac {\eta}{m} \cdot g^{(l)}_{ji}$$
역전파의 한계
MLP에서 특히 임의의 모수들을 비최적으로 초기화했을 때, 역전파로 가중치들을 업데이트하는 계산 속도가 매우 느리다. 역전파에서 사용되는 손실 함수는 비 볼록 함수(Non-convex Function)에다가 고차원이며 심지어 하나 이상의 극소값(Local Minima)을 갖는다. 따라서 MLP의 학습이 수렴한다는 보장도 없고 수렴한다 해도 수렴 속도가 매우 느리거나 수렴 값이 최적 값이라는 보장도 할 수 없다.
인공 신경망의 최적화(Optimization of Artificial Neural Network)
가중치 초기화(Weight Initialization)

인공 신경망에서 하나 이상의 극소값을 가질 수 있다고 했는데, 그 이유는 모델의 대칭성(Symmetry)에 있다. 같은 모델이지만 다른 순서로 배치될 수 있는 여러 가지 가능성 때문에 모델의 수렴도 다양하다.
위의 그림은 각 가중치를 초기화에 따른 수렴 모델을 보여준다. 가장 오른쪽, 임의로 가중치를 초기화했을 때, 가장 좋은 성능을 보이는데, 임의성이 모델의 대칭성을 어느 정도 깰 수 있기에 다른 모델에 비해 잘 수렴했다고 할 수 있다.
He-et-al Random Initialization Heuristic:
For neural networks with ReLU neurons, it is recommended to use:
$$w_{ij} \sim \mathcal {N} (0, \sigma^2) \text { with } \sigma = \sqrt {\frac {2} {\text{# of input connections}}}$$
and where $\mathcal {N}$ is the Gaussian distribution.※ 예를 들어, 50개의 입력 특성, 200개의 은닉 뉴런, 1개의 출력을 갖는 2 계층 인공 신경망을 가정하자. 첫 번째 계층에서는 $\sigma = \sqrt {\frac{2}{50}}$을, 두 번째 계층에서는 $\sigma \sqrt{\frac {2}{200}}$을 이용해서 가중치를 초기화한다.
많은 양의 학습 셋이 주어졌을 때, 가설 공간이 $\mathcal {H} = {h_W: \mathbb {R}^n \rightarrow \mathbb {R}^c | W \in \vee}$로, 미분 가능한 볼록 손실 함수는 $l(h_W(x), y)$로 정의된다고 하자.
인공 신경망을 학습하기 위해서 다음의 함수를 최소화한다.
$$J(W) = \frac {1}{m} \sum^m_{t = 1} l (h_W(x_t), y_t) = \frac {1}{m} \sum^m_{i = t} J_t(W)$$
일반적인 경사 하강법을 더 효율화하기 위해 조금 변형된 경사 하강법을 사용한다.
- 배치 경사 하강법(Batch Gradient Descent)
- 확률적 경사 하강법(Stochastic Gradient Descent)
- 미니-배치 경사 하강법(Mini-Batch Gradient Descent)
배치 경사 하강법(Batch Gradient Descent)
- 종료 시까지 다음 업데이트를 반복한다.
- $$W \leftarrow W - \frac {\eta}{m} \sum^m_{t = 1} \nabla J_t(W)$$
- 추가적으로 반복마다 학습률(Learning Rate) $\eta$를 조정할 수 있다.
BGD는 가중치를 하나씩 업데이트하지 않고 행렬 $W$을 통해 한번에 모든 가중치를 업데이트해 $m$개 학습 셋을 학습한다.
다음의 표는 BGD의 장점과 단점을 나열하였다.

확률적 경사 하강법(Stochastic Gradient Descent)
- 종료 시까지 다음 업데이트를 반복한다.
- 임의로 선택한 $t \in \{ 1, \cdots, m \}$에 대해서
- $$W \leftarrow W - \eta \nabla J_t(W)$$
- 추가적으로 반복마다 학습률(Learning Rate) $\eta$를 조정할 수 있다.
SGD는 각 반복마다 임의로 고른 가중치 $\nabla J_t(W)$에 대해서만 업데이트한다. 즉, $m$번의 반복을 통해 $m$개의 학습 셋을 학습한다.
※ SGD의 변형 1)
- 학습 셋의 순서를 섞는다.
- 종료 시까지 다음 업데이트를 반복한다.
- 각 $t \in \{ 1, \cdots, m \}$에 대해서
- $$W \leftarrow W - \eta \nabla J_t(W)$$
- 추가적으로 반복마다 학습률(Learning Rate) $\eta$를 조정할 수 있다.
※ SGD의 변형 2)
- 종료 시까지 다음 업데이트를 반복한다.
- 학습 셋의 순서를 섞는다.
- 각 $t \in \{ 1, \cdots, m \}$에 대해서
- $$W \leftarrow W - \eta \nabla J_t(W)$$
- 추가적으로 반복마다 학습률(Learning Rate) $\eta$를 조정할 수 있다.
배치 경사 하강법과 확률적 경사 하강법의 비교
배치 경사 하강법 확률적 경사 하강법 - 한 번의 반복으로 1번의 업데이트를 수행한다.
- $m$이 매우 클 때, 수렴 속도가 느리다.
- 행렬 대 행렬 계산으로 쉽게 계산할 수 있다.
- $\eta$가 작다면 $\nabla J$은 $J(W)$ 방향으로 서서히 감소한다.
- 극소값으로 수렴한다.
- 병렬적으로 구현이 가능하다.
- 최솟값에 가까워졌을 때, 그 값을 비교적 잘 찾는다.- 한 번의 반복으로 $m$번의 업데이트를 수행한다.
- $m$이 매우 클 때, 수렴 속도가 빠르다.
- 많은 계산식을 요구한다.
- $\nabla J_t$로 $\nabla J$에 근사화한다.
- 근사값의 분산이 커, $J(W)$가 근처의 극소값에서 변동한다.
- 실시간으로 연산이 가능하다.
- 최소값에 가까워졌을 때, 그 값을 정확히 잘 찾지 못한다.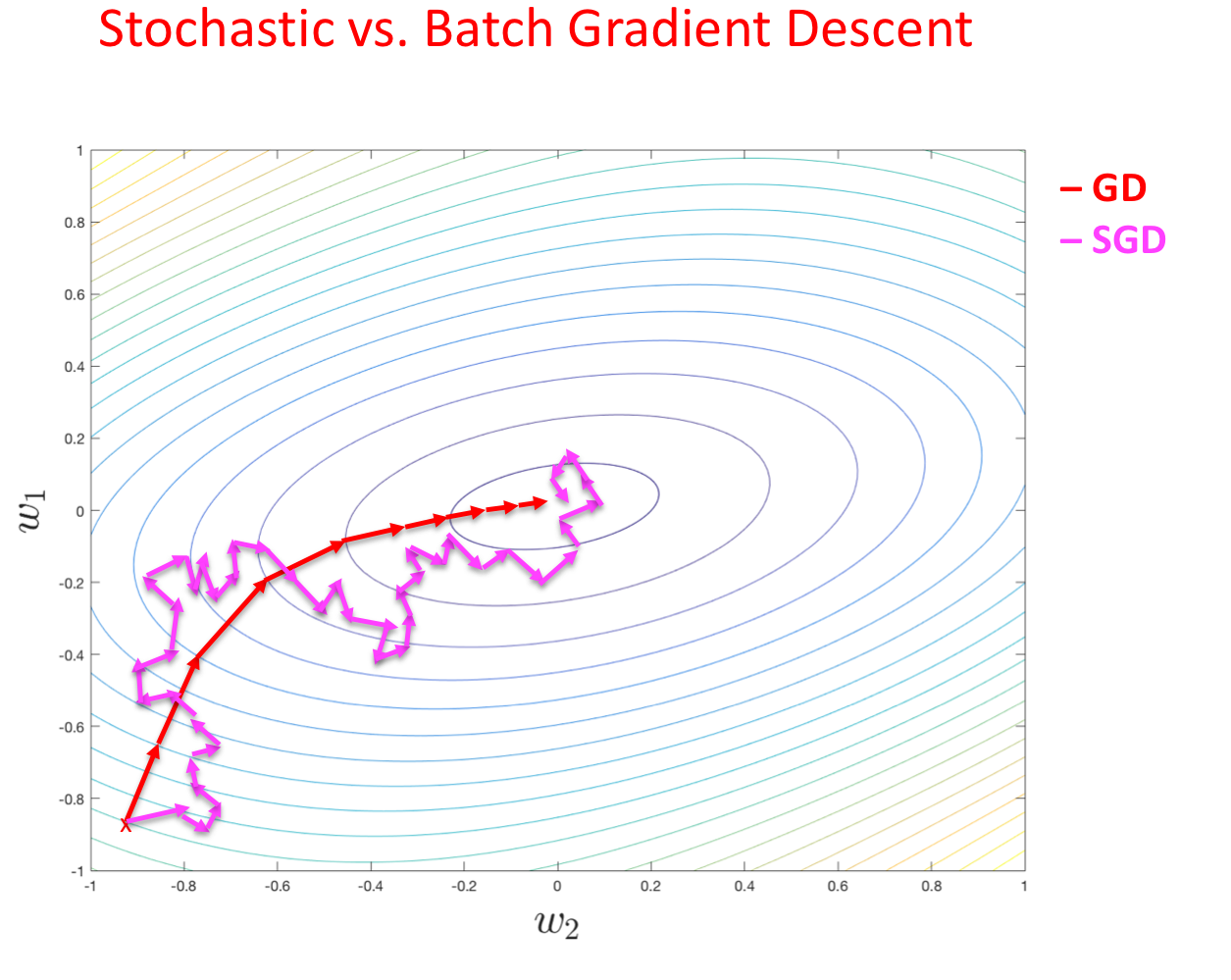
미니-배치 경사 하강법(Mini-batch Gradient Descent)
- 종료 시까지 다음 업데이트를 반복한다.
- 학습 셋의 순서를 섞는다. $T = {1, \cdots, m}$
- 대충 $b$만큼의 크기를 갖는 $q$개의 배치 $B_1, \cdots, B_q$로 $T$를 나눈다.
- 모든 배치에 대해서 각 $k = {1, \cdots, q}$
- $$W \leftarrow W - \eta \cdot \frac {1}{|B_k|} \sum_{i \in B_k} \nabla J_t(W)$$
- 추가적으로 반복마다 학습률(Learning Rate) $\eta$를 조정할 수 있다.
미니 배치 경사 하강법은 배치 경사 하강법과 확률적 경사 하강법을 적절히 섞은 경사 하강법이다. $b = 1$일 때, SGD의 절차와 같고, $b = m$일 때, BGD의 절차와 같다.
학습률 $\eta$ 조정하기
- 초기화 $\eta \leftarrow \eta_0$
- 조정 $\eta \leftarrow A(\eta, \eta_0, s), \text { where } s \text { is the number of updates} $
학습률을 조정하는 데에는 몇 가지 방법들이 있다.
상수(Constant)
$A(\eta, \eta_0, s) = \eta$
단계적 감쇠(Step Decay)
$A(\eta, \eta_0, s) = \begin {cases} \alpha \cdot \eta & s \mod S = 0 \\ \eta & \text {otherwise} \end {cases} \\ \ \ \ \ , 0 < \alpha < 1, \ S \in \mathbb {N}$
기하급수적 감쇠(Exponential Decay)
$A(\eta, \eta_0, s) = \eta_0 \exp (-\alpha \cdot s), \text { where } \eta_0, \alpha \text{ are hyperparameters}$
$\frac {1}{t}$ 감쇠($\frac {1}{t}$ Decay)
$A(\eta, \eta_0, s) = \frac {\eta_0}{1 + \alpha \cdot s}, \text { where } \eta_0, \alpha \text{ are hyperparameters}$
병적인 곡률(Pathological Curvature)

인공 신경망의 오차 함수는 오른쪽 그림과 같은 병적인 곡률을 갖는다. 이런 형태가 최소 오차를 찾는 속도를 저하한다.
오차 함수의 곡률은 함수의 헤시안(Hessian)의 고윳값으로 관찰한다. (※ 이계도 함수의 원리로 곡선의 모양을 파악한다.)
$$H = \left (\frac {\partial^2 \mathcal {E}(\theta)}{\partial \theta_i \partial \theta_j} \right )_{ij}$$
$$\lambda_1, \cdots, \lambda_{|\theta|} = eigvals(H)$$
가장 큰 고윳값과 가장 작은 고윳값의 비율을 조건수(Condition Number)라고 하는데, 이 값이 더 클수록 수렴 속도가 더 느리다.

선형적인 모델에서의 헤시안 분석(Hessian Analysis in Linear Model)
가장 간단한 선형 모델 $y = \mathbf {w}^{\top} \mathbf {x}$과 MSE 오차 함수 $\mathcal {E} (\mathbf {w}) = \mathbb {E} [0.5 \cdot (1 - yt)^2]$를 가정하자.
오차 함수의 헤시안은 다음과 같다.
$$H = \frac {\partial^2 \mathcal {E}}{\partial \mathbf {w}^2} = \mathbb {E} [\mathbf {x} \mathbf {x}^{\top}]$$
즉, 헤시안 값은 정렬되지 않은 데이터의 공분산이다.
조건수(Condition Number):
$\mathbf {x} \sim \mathcal {N} (\mathbf{\mu}, \sigma^2 \mathbf {I})$를 가정했을 때, 헤시안은 $H = \sigma^2 \mathbf{I} + \mathbf {\mu}\mathbf {\mu}^{\top}$이며 조건수는 다음과 같다.
$$\frac {\lambda_1}{\lambda_d} = 1 + \frac {||\mathbf{\mu}||^2}{\sigma^2}$$
※ 데이터를 0으로 정렬하기만 해도($\mu = 0$), 조건수는 줄어든다.
일반적인 모델에서의 헤시안 분석(Hessian Analysis in General Model)
더보기더보기더보기일반적인 인공 신경망의 헤시안은 다음과 같다.
$$H = \frac {\partial^2 \mathcal {E}}{\partial \theta^2}
= \frac {\partial \mathbf {Y}^{\top}}{\partial \theta} \frac {\partial^2 \mathcal {E}}{\partial \mathbf {Y}^2} \frac {\partial \mathbf {Y}}{\partial \theta} + \frac {\partial \mathcal {E}}{\partial \mathbf {Y}} \frac {\partial^2 \mathbf {Y}}{\partial \theta^2}$$where $\mathbf {Y}$ is the vector containing the predictions for all data points.
MSE 오차 함수를 가정했을 때, 특정 뉴런 $k$에 연관된 모수들의 헤시안은 다음과 같다.
$$[H_k]_{jj'} = \frac {\partial^2 \mathcal {E}}{\partial w_{jk} \partial w_{j'k}} = \mathbb {E} [a_j a_{j'} \delta^2_k] + \mathbb {E} [a_j \frac {\partial \delta_k}{\partial w_{j'k}} \cdot (y - t)]$$
where $\delta_k$ is a shortcut notation for $\frac {\partial \mathcal {E}}{\partial z_k}$
이때, $a_j a_{j'}$와 $\delta^2_k$가 독립적이고, $\delta_k$가 $w_{j'k}$에 영향을 받지 않을 때, 다음과 같은 헤시안을 구할 수 있다.
$$H_k \approx \mathbb {E} [\mathbf {a} \mathbf {a}^{\top}] \cdot \mathbb {E} [\delta^2_k]$$
선형적인 모델에서 봤던 구조와 비슷하며, 마찬가지로 활성화를 정렬하는 것이 조건수를 줄이는 데 도움이 됨을 예상할 수 있다.
헤시안 분석을 통한 결론
인공 신경망의 최적화를 하기 위해서는 경사 하강법의 수렴 속도를 증가해야 한다.
↓
수렴 속도가 증가하려면 오차 함수의 곡률을 살펴봐야 하는데, 이는 헤시안을 통해 분석이 가능하다.
↓
헤시안으로 구한 고유값으로 조건수를 계산한다. 이 조건수가 작을 수록 수렴 속도가 높다.
↓
조건수를 감소시키려면 데이터와 모든 계층의 활성화를 0으로 정렬해야 한다.
Q. 데이터를 어떻게 정규화(Standardization)하는가?
A. $\tilde {x}_{ij} = \frac {x_{ij} - \mu_j}{\sigma_j}$Q. 활성화를 정렬하려면 어떻게 해야할까?
A. $g(0) = 0$을 만족하는 활성화 함수를 선택하면 된다. 예로는, ReLU $\max(0, z)$, 정렬된 소프트플러스(Centered Softplus) $\log (1 + \exp(z)) - \log 2$, 하이퍼볼릭 탄젠트 $tanh(z)$가 있다. 반대로 사용해야 하지 말아야 비정렬된 함수는 표준 소프트플러스(Standard Softplus) $\log (1 + \exp (z))$, 로지스틱 시그모이드 $\exp (z) / (1 + \exp (z))$가 있다.
모멘텀을 이용한 확률적 경사 하강법(SGD with Momentum)
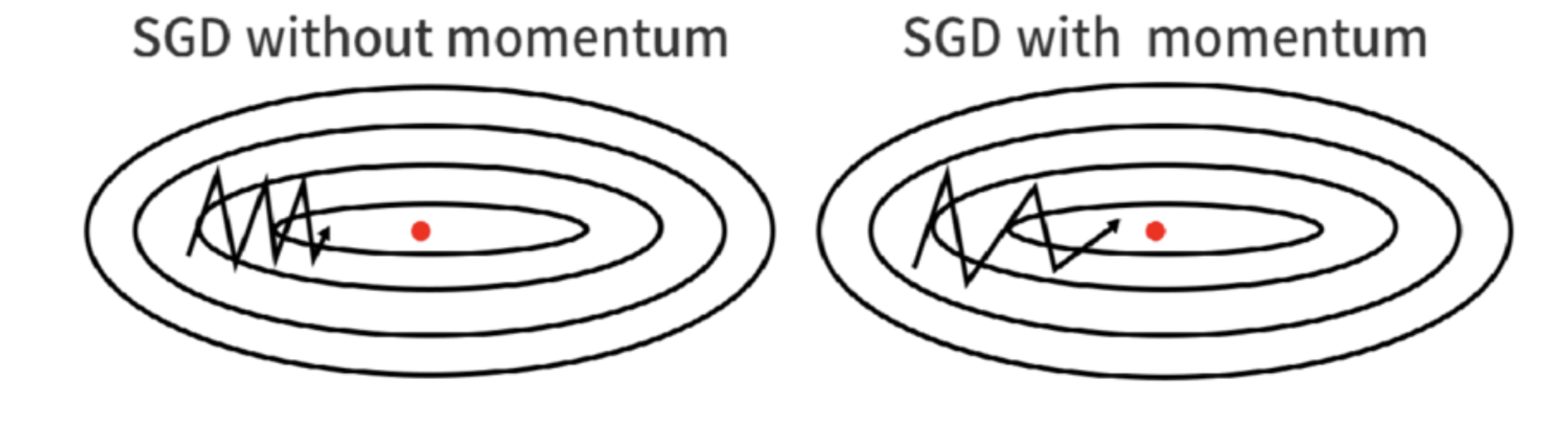
모멘텀은 한국어로 관성, 탄성을 의미한다. 모멘텀을 이용한 SGD는 매 업데이트마다 극소값 방향으로 수렴할 뿐만 아니라, 지난 업데이트의 방향까지 고려하여 극소값 방향으로 수렴한다. 이렇게 하면 최적화 문제에서 곡률이 작은 방향으로 빨리 수렴할 수 있다.
SGD(Stochastic Gradient Descent):
$$\begin {align*}
\theta &= \theta - \gamma \cdot \frac {\partial \mathcal {E}_k}{\partial \theta} & \text { with } k \sim \{ 1, \cdots, N \}
\end {align*}$$
where $\gamma$ is the learning rate.
모멘텀을 이용한 SGD의 절차는 다음과 같다.$$\begin {align*}
\nabla &= \mu \nabla + \frac {\delta \mathcal {E}_k}{\delta \theta} & \text { with } k \sim \{ 1, \cdots, N \} \\
\theta &= \theta - \gamma \nabla
\end {align*}$$where $\gamma$ is learning rate and $\mu$ is the momentum.
※ 일반적으로 사용되는 학습률과 모멘텀은 각각 $\gamma = 0.01$과 $\mu = 0.9$이다.
인공 신경망의 정규화(Regularization of Artificial Neural Network)
주어진 데이터에 대해 최적화된 인공 신경망이 새로운 데이터까지 잘 예측할 수 있을까? 예측을 잘 하는 인공 신경망 모델을 일반화(Generalization)할 수 있을까? 우선 정규화에 앞서서 인공 신경망에서 사용되는 손실 함수부터 알아보자.
힌지 손실(Hinge Loss)
퍼셉트론 손실 함수(Perceptron Loss Function):
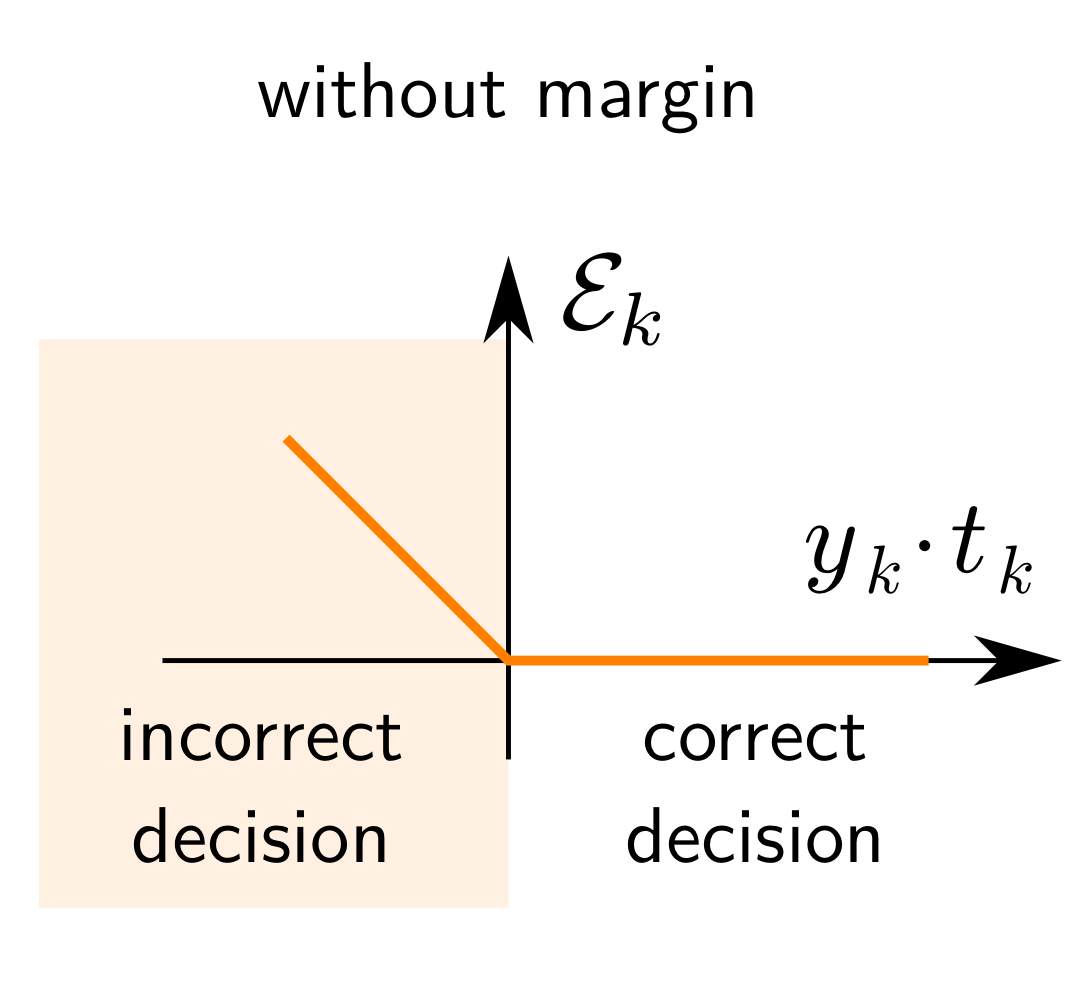
$$\mathcal {E}_k (\theta) = \max (0, -y_k t_k)$$
which becomes zero as soon as the current data point is being correctly classified.
퍼셉트론 손실 함수에서 마진(Margin) $m$을 추가한 힌지 손실을 사용한다. 이렇게 되면, 결정 경계(Decision Boundary)에 여유를 부여해서 어느 정도 오차에 관대한 분류 혹은 회귀를 할 수 있다.$$\mathcal {E}_k (\theta) = \max (0, 1 - y_k t_k)$$
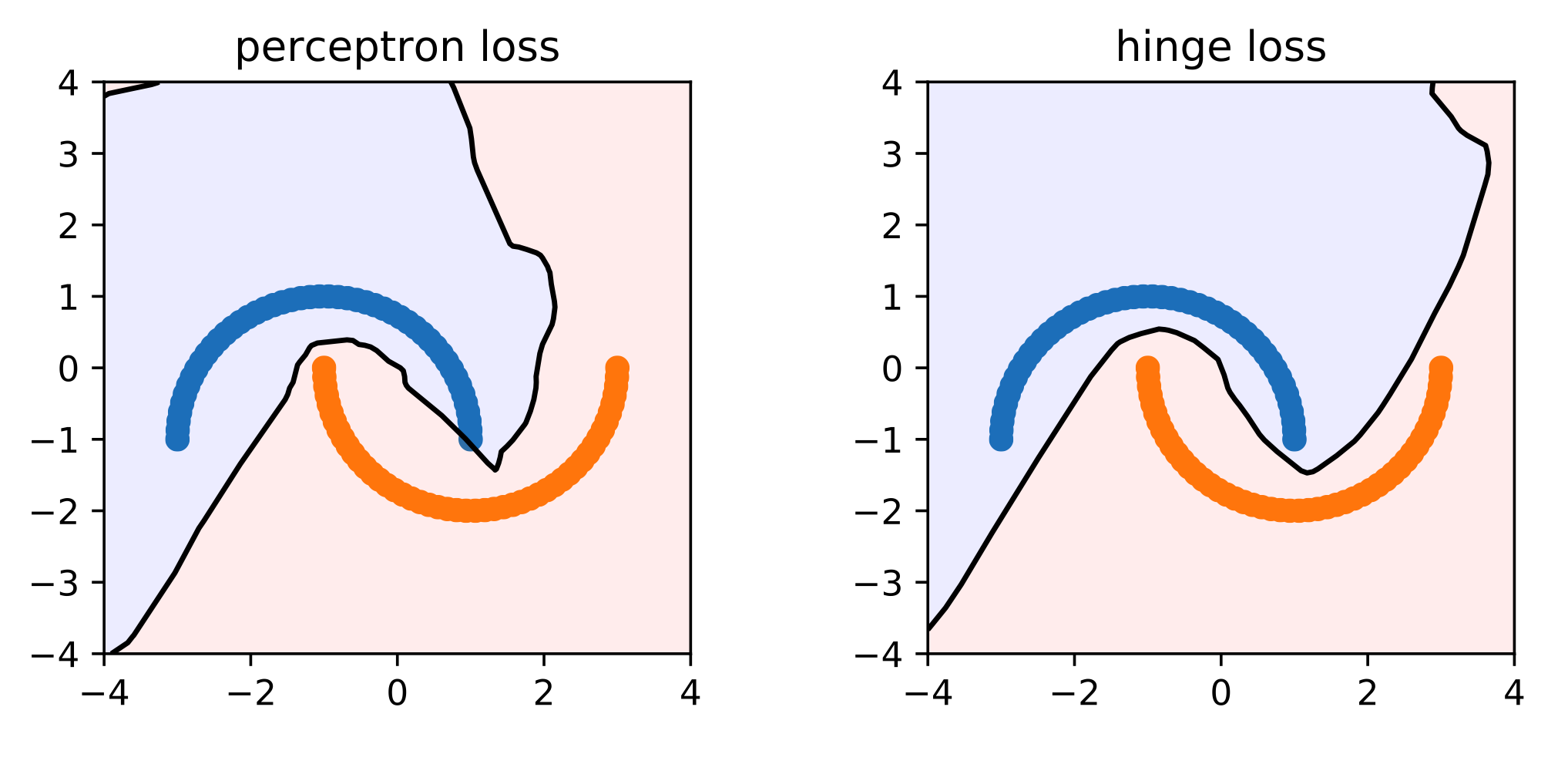
퍼셉트론 손실과 힌지 손실의 성능 차이 ※ 참고
명칭 공식 마진 이상치 퍼셉트론 손실(Perceptron Loss) $\max (0, -y \cdot t)$ X O 힌지 손실(Hinge Loss) $\max (0, 1 - y \cdot t)$ O O 제곱 힌지 손실(Squared Hinge Loss) $\max (0, 1 - y \cdot t)^2$ O X 로그 손실(Log Loss) $\log (1 + \exp (- y \cdot t))$ O O
인공 신경망 정규화의 필요성
만약에 가중치를 어떤 인수(Factor)로 곱한다면 마진의 크기 $m$가 상대적으로 변하게 된다. 이러한 현상을 방지하기 위해 인공 신경망 모델 자체를 정규화할 필요가 있다.
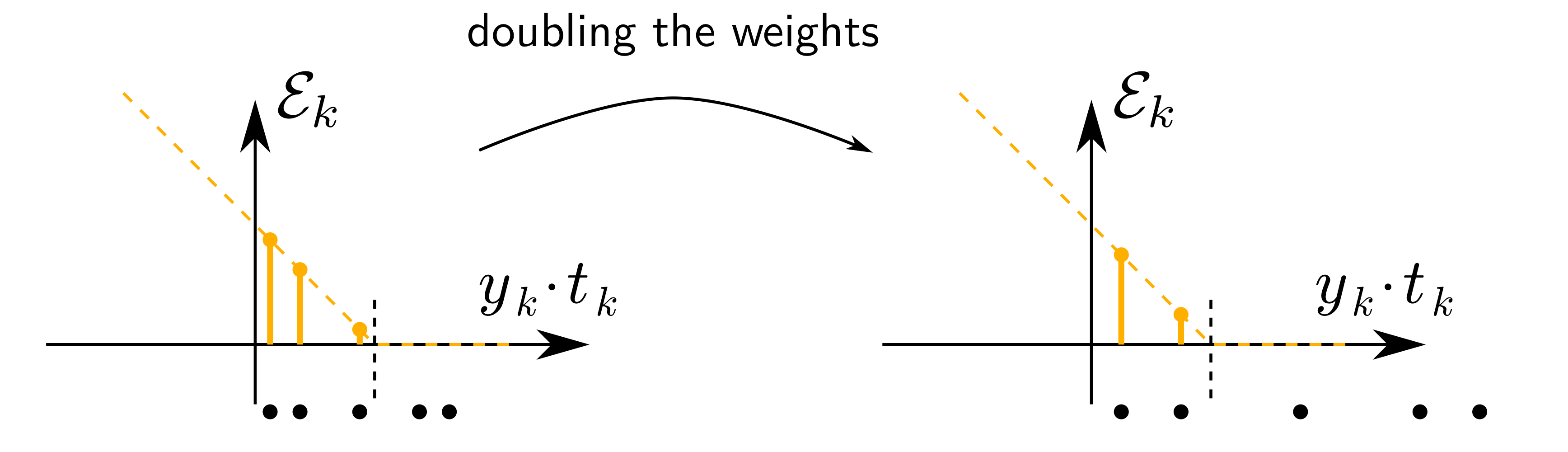
다양한 정규화 방법들
가중치 감쇠(Weight Decay)
- $L_1$ 정규화
$$J(W, \lambda) = J(W) + \frac {\lambda}{m} \sum_{\mathbf {w} \in W} |\mathbf {w}|$$
$$\mathbf {w} \leftarrow \mathbf {w} - \eta \left ( \frac {\partial}{\partial \mathbf {w}} J(W) + \frac {\lambda}{m} (\mathbb {I} \{ \mathbf {w} \geq 0 \} - \mathbb {I} \{ \mathbf {w} < 0 \}) \right )$$ - $L_2$ 정규화
$$J(W, \lambda) = J(W) + \frac {\lambda}{2m} \sum_{w \in W} |w|^2$$
$$\mathbf {w} \leftarrow \mathbf {w} - \eta \left ( \frac {\partial}{\partial \mathbf {w}} J(W) + \frac {\lambda}{m} \mathbf {w} \right )$$
데이터 섭동(Data Perturbation)
입력 학습 셋과 레이블에 임의의 섭동을 추가한다. (※ 예) 가우시안 노이즈(Gaussian Noise))
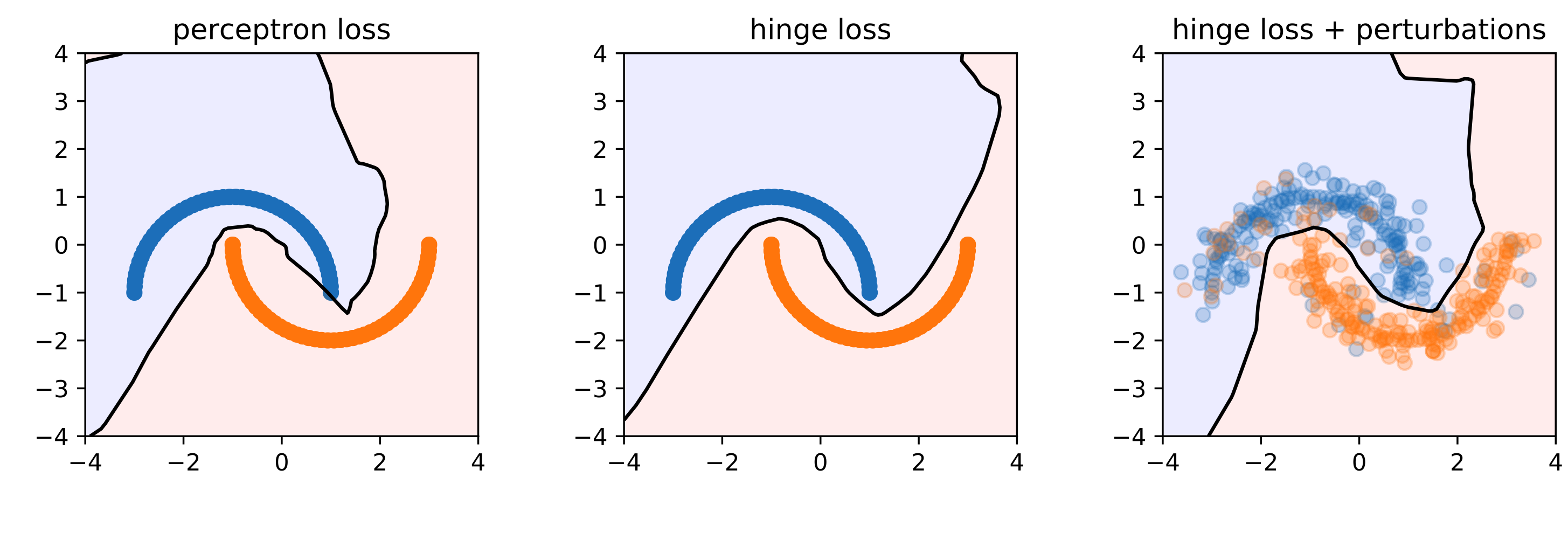
표현 섭동(Representation Perturbation)

드롭아웃(Dropout)은 학습 시, 임의로 뉴런들을 활성화하고 비활성화하여 모델의 복잡도(Model Complexity)를 줄이는 방법을 말한다. 미니 배치의 크기가 1일 때($b = 1$) 드롭아웃의 학습 절차는 다음과 같다.
- 학습할 데이터 셋 $\mathbf {x}$를 선택한다.
- $1 - p$ 확률로 뉴런들을 제외한다.
- 남은 뉴런에 대해서만 역전파를 실행한다.
- 가중치를 업데이트한다.
- 1.로 복귀한다.
학습 후에 다음의 절차로 새로운 데이터들을 예측할 수 있다.
- 모든 가중치를 $p$로 곱한다.
- 검정할 데이터 셋 $\mathbf {x}$를 선택한다.
- $\mathbf {x}$에 대해서 순전파를 실행한다.
- 출력 $h(\mathbf {x})$를 계산한다.
노이즈 학습(Noise Training)
확률적 경사 하강법은 일반적인 경사 하강법보다 정규화 효과를 가진다.
조기 중단(Early Stopping)
검증 오차(Validation Error)가 증가하거나 지체되기 전에 학습을 중단하여 오버 피팅(Overfitting)을 방지한다.

1. Richard O. Duda, Peter E. Hart, and David G. Stork. 2000. Pattern Classification (2nd Edition). Wiley-Interscience, USA.
2. Müller, K.R., Montavon, G. (2021). Lecture on Machine Learning 1-X. Technische Universität Berlin, Berlin, Germany.
3. He, K., Zhang, X., Ren, S., & Sun, J. (2015). Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE international conference on computer vision (pp. 1026-1034).
4. Martens, J. (2010, June). Deep learning via hessian-free optimization. In ICML (Vol. 27, pp. 735-742).
반응형'Informatik' 카테고리의 다른 글
[Machine Learning] 분류의 성능 평가 지표(Evaluation Metrics of Classification) (0) 2022.02.22 [Machine Learning] 나이브 베이즈 분류(Naïve Bayes Classification) (0) 2022.02.21 [Machine Learning] 피셔의 선형 판별 분석(Fisher Linear Discriminant Analysis) (5) 2022.02.17 [Machine Learning] 공분산 행렬(Covariance Matrix) (0) 2022.02.16 [Machine Learning] 상관계수(Correlation Coefficient) (0) 2022.02.16